
Redes neurais profundas e o deep learning se tornaram populares nos últimos anos graças a avanços nas pesquisas, com AlexNet, VGG, GoogleNet, e ResNet. Em 2015, com o ResNet, a performance do reconhecimento de imagens em larga escala presenciou uma melhora enorme em termos de precisão e ajudou a aumentar a popularidade das redes neurais profundas.
Este artigo discute o uso da rede neural profunda básica para resolver um problema de reconhecimento de imagem. Aqui a ênfase está mais na técnica em geral e no uso de uma biblioteca do que em aperfeiçoar o modelo. A Parte 2 explica como melhorar os resultados.
Eu quis usar a rede neural profunda para resolver algo além de uma versão “Olá, mundo” do reconhecimento de imagens — reconhecimento de letras cursivas com a base de dados MNIST, por exemplo. Depois de passar pelo primeiro tutorial sobre as bibliotecas do TensorFlow e do Keras, comecei com o desafio de classificar uma imagem como um chihuahua (raça de cão) ou um muffin a partir de um conjunto de imagens parecidas.
Os dados incluídos neste artigo foram formados pela combinação entre esta fonte e pesquisas na internet, aplicando algumas técnicas básicas de processamento de imagens. As imagens desse conjunto foram coletadas, usadas e fornecidas sob a política de uso aceitável de imagens do Creative Commons. O uso pretendido é para pesquisa científica em reconhecimento de imagens usando redes neurais artificiais, utilizando a biblioteca do TensorFlow e do Keras. Essa solução aplica as mesmas técnicas fornecidas na classificação básica do TensorFlow.
Basicamente, não existem pré-requisitos para este artigo, mas se você quiser seguir o código, será útil possuir conhecimento básico de Python e numpy, bem como passar pela biblioteca do TensorFlow e do Keras.

Importe os dados
Clone o repositório do Git
$ git clone https://github.com/ScrapCodes/image-recognition-tensorflow.git
$ cd image-recognition-tensorflow
$ python
>>>
Importe as bibliotecas de TensorFlow, Keras e outras que ajudem
Utilizei as do TensorFlow e do Keras para rodar o machine learning e a biblioteca Pillow Python para o processamento de imagens.
Usando o pip, elas podem ser instaladas no macOS da seguinte forma:
sudo pip install tensorflow matplotlib pillow
Observação: o uso do sudo ser exigido ou não depende de como o Python e o pip estão instalados no seu sistema. Os sistemas configurados com um ambiente virtual podem não precisar do sudo.
Importando as bibliotecas Python:
# TensorFlow and tf.keras
import tensorflow as tf
from tensorflow import keras
# Helper libraries
import numpy as np
import matplotlib.pyplot as plt
import glob, os
import re
# Pillow
import PIL
from PIL import Image
Carregue os dados
Uma função Python para pré-processar as imagens de entrada. Para imagens que serão convertidas em arranjos numpy, elas devem ter as mesmas dimensões:
# Use Pillow library to convert an input jpeg to a 8 bit grey scale image array for processing.
def jpeg_to_8_bit_greyscale(path, maxsize):
img = Image.open(path).convert('L') # convert image to 8-bit grayscale
# Make aspect ratio as 1:1, by applying image crop.
# Please note, croping works for this data set, but in general one
# needs to locate the subject and then crop or scale accordingly.
WIDTH, HEIGHT = img.size
if WIDTH != HEIGHT:
m_min_d = min(WIDTH, HEIGHT)
img = img.crop((0, 0, m_min_d, m_min_d))
# Scale the image to the requested maxsize by Anti-alias sampling.
img.thumbnail(maxsize, PIL.Image.ANTIALIAS)
return np.asarray(img)
Uma função Python para carregar o conjunto de dados das imagens e dispor em arranjos numpy:
def load_image_dataset(path_dir, maxsize):
images = []
labels = []
os.chdir(path_dir)
for file in glob.glob("*.jpg"):
img = jpeg_to_8_bit_greyscale(file, maxsize)
if re.match('chihuahua.*', file):
images.append(img)
labels.append(0)
elif re.match('muffin.*', file):
images.append(img)
labels.append(1)
return (np.asarray(images), np.asarray(labels))
Nós devemos dimensionar as imagens em um tamanho padrão menor do que a resolução da imagem real. Essas imagens são maiores do que 170x170, então dimensionaremos todas para 100x100 para o processamento:
maxsize = 100, 100
Para carregar os dados, vamos executar as funções a seguir e carregar os conjuntos de dados de treinamento e teste:
(train_images, train_labels) = load_image_dataset('/Users/yourself/image-recognition-tensorflow/chihuahua-muffin', maxsize)
(test_images, test_labels) = load_image_dataset('/Users/yourself/image-recognition-tensorflow/chihuahua-muffin/test_set', maxsize)
train_images e train_lables é o conjunto de dados de treinamento.
test_images e test_labels é o conjunto de dados de teste para validar a performance do modelo diante de dados não vistos.
Por fim, nós definimos os nomes de classes para nosso conjunto de dados. Devido ao fato de que nossos dados possuem apenas duas classes (uma imagem pode ser um chihuahua ou um muffin), temos class_names da seguinte forma:
class_names = ['chihuahua', 'muffin']
Explore os dados
Nesse conjunto de dados, nós temos 26 exemplos de treinamento, tanto de imagens de chihuahuas quanto de muffins:
train_images.shape
(26, 100, 100)
Cada imagem possui sua respectiva label: 0 ou 1. O 0 indica um class_names[0], quer dizer, um chihuahua; e o 1 indica class_names[1], ou seja, um muffin:
print(train_labels)
[0 0 0 0 1 1 1 1 1 0 1 0 0 1 1 0 0 1 1 0 1 1 0 1 0 0]
Para o conjunto de teste, temos 14 exemplos, 7 para cada classe:
test_images.shape
(14, 100, 100)
print(test_labels)
[0 0 0 0 0 0 0 1 1 1 1 1 1 1]
Visualize o conjunto de dados
Usando a biblioteca Python matplotlib.pyplot, nós podemos visualizar nossos dados. Certifique-se de que você possui a biblioteca matplotlib instalada.
A seguir, a função de ajuda Python nos ajudará a produzir essas imagens na tela:
def display_images(images, labels):
plt.figure(figsize=(10,10))
grid_size = min(25, len(images))
for i in range(grid_size):
plt.subplot(5, 5, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(images[i], cmap=plt.cm.binary)
plt.xlabel(class_names[labels[i]])
Vamos visualizar o conjunto de dados de treinamento como segue:
display_images(train_images, train_labels)
plt.show()
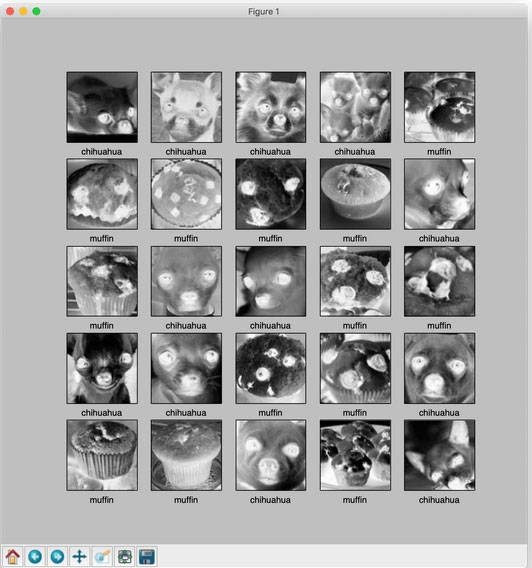 Observação: as imagens ficam em escala de cinza e são cortadas no passo do pré-processo de nossas imagens na hora de carregar.
Observação: as imagens ficam em escala de cinza e são cortadas no passo do pré-processo de nossas imagens na hora de carregar.
De forma similar, podemos visualizar o conjunto de dados de teste. Tanto o conjunto de treinamento quanto o de teste são bastante limitados, então sinta-se livre para usar a busca do Google e adicionar mais exemplos para ver como as coisas performam ou melhoram.
Pré-processamento dos dados
Classificar as imagens em valores entre 0 e 1
train_images = train_images / 255.0
test_images = test_images / 255.0
Construa o modelo
Configure as camadas
Nós usamos quatro camadas no total. A primeira é simplesmente para achatar o conjunto de dados em um arranjo único e não precisa de treinamento. As outras três são densas e usam a função sigmoide para ativação:
# Setting up the layers.
model = keras.Sequential([
keras.layers.Flatten(input_shape=(100, 100)),
keras.layers.Dense(128, activation=tf.nn.sigmoid),
keras.layers.Dense(16, activation=tf.nn.sigmoid),
keras.layers.Dense(2, activation=tf.nn.softmax)
])
Compile o modelo
O otimizador é o gradiente descendente estocástico (SGD):
sgd = keras.optimizers.SGD(lr=0.01, decay=1e-5, momentum=0.7, nesterov=True)
model.compile(optimizer=sgd,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
Treine o modelo
model.fit(train_images, train_labels, epochs=100)
Três iterações de treinamento aparecem:
....
Epoch 98/100
26/26 [==============================] - 0s 555us/step - loss: 0.3859 - acc: 0.9231
Epoch 99/100
26/26 [==============================] - 0s 646us/step - loss: 0.3834 - acc: 0.9231
Epoch 100/100
26/26 [==============================] - 0s 562us/step - loss: 0.3809 - acc: 0.9231
Avalie a precisão
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
14/14 [==============================] - 0s 8ms/step
('Test accuracy:', 0.7142857313156128)
A precisão do teste é menor do que a do treinamento. Isso indica que o modelo se sobreajustou aos dados. Existem técnicas para superar isso, as quais discutiremos mais adiante. Esse modelo é um bom exemplo do uso da API, mas está longe de ser perfeito.
Com os avanços recentes no reconhecimento de imagens e usando mais dados de treinamento, podemos performar muito melhor nesse desafio de conjunto de dados.
Faça previsões
Para fazer previsões, podemos simplesmente prever no modelo gerado:
predictions = model.predict(test_images)
print(predictions)
[[0.6080283 0.3919717 ]
[0.5492342 0.4507658 ]
[0.54102856 0.45897144]
[0.6743213 0.3256787 ]
[0.6058993 0.39410067]
[0.472356 0.5276439 ]
[0.7122982 0.28770176]
[0.5260602 0.4739398 ]
[0.6514299 0.3485701 ]
[0.47610506 0.5238949 ]
[0.5501717 0.4498284 ]
[0.41266635 0.5873336 ]
[0.18961382 0.8103862 ]
[0.35493374 0.64506626]]
Por fim, exiba as imagens e veja como o modelo performou no conjunto de teste:
display_images(test_images, np.argmax(predictions, axis = 1))
plt.show()
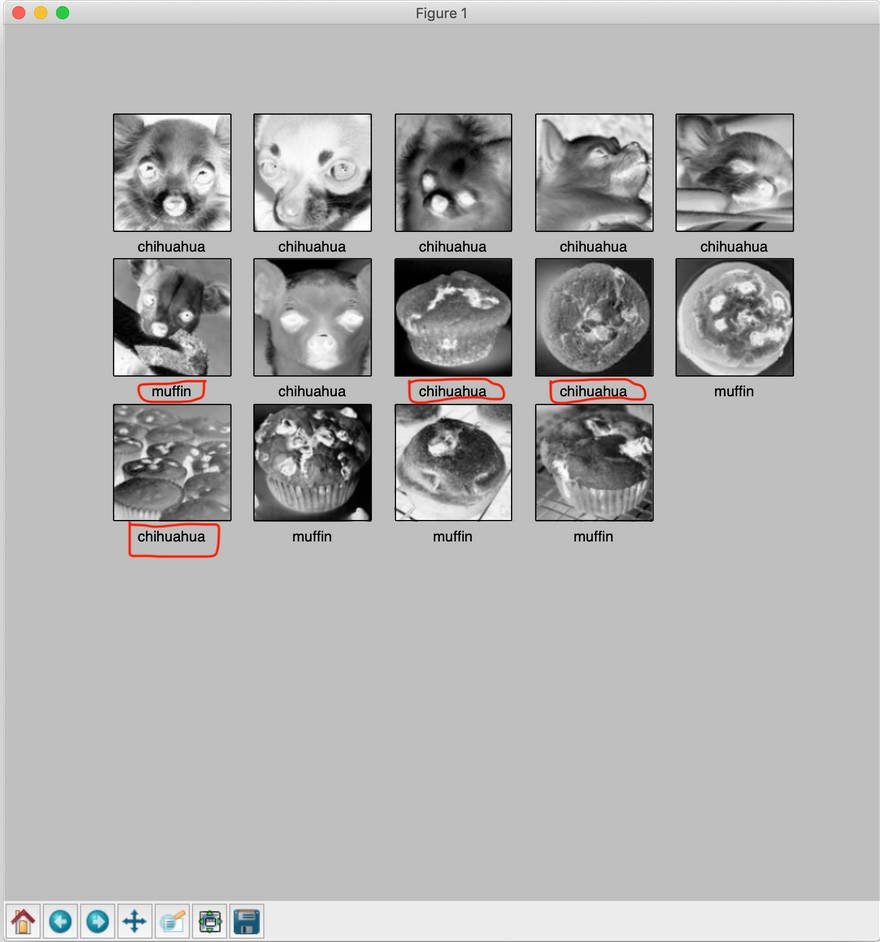
Conclusão
Neste artigo existem algumas classificações erradas no nosso resultado, como foi destacado na imagem anterior. Até agora, está longe do perfeito. Na Parte 2, aprenderemos a melhorar o treinamento.
...
Quer ler mais conteúdo especializado de programação? Conheça a IBM Blue Profile e tenha acesso a matérias exclusivas, novas jornadas de conhecimento e testes personalizados. Confira agora mesmo, consiga as badges e dê um upgrade na sua carreira!
.....
Participe da Maratona Behind the Code 2020, um desafio para desenvolvedores e entusiastas da tecnologia! Além de concorrer a prêmios, você ainda tem acesso a conteúdos e serviços gratuitos. Não perca essa chance, as inscrições vão até 7 de agosto!
Categorias



















