
No mundo da TI, o Apache Kafka (ao qual será referido apenas como Kafka) é, atualmente, a plataforma mais popular de distribuição de mensagens ou fluxo de informações. Qualquer aplicação que funcione com qualquer tipo de informação (registros, eventos ou outros) e requeira que essa informação seja transferida, além de transformada ao se mover por seus componentes, pode se beneficiar do Kafka. Ele começou como um projeto no LinkedIn e depois seu código foi aberto com o objetivo de facilitar a sua adoção. Ao longo dos últimos anos, continuou sendo um projeto de código aberto e se desenvolveu bastante. Grandes nomes da tecnologia da informação o utilizam em seu ambiente de produção.
Alguns dos componentes básicos do Kafka são:
Broker — é onde os dados enviados ao Kafka são armazenados. Eles são responsáveis por recebê-los e armazená-los assim que chegam. O broker também fornece-os quando requisitado. Muitos dos brokers Kafka trabalham juntos na formação de um cluster. O Kafka utiliza o Apache ZooKeeper para armazenar metadados sobre o cluster. Os brokers usam esses metadados na detecção de falhas (por exemplo as do broker) e se recuperar delas.
Produtor — é uma entidade que envia dados ao broker. Existem diferentes tipos de produtores. O Kafka vem com o seu próprio, escrito em Java, mas existem muitas outras bibliotecas Kafka de clientes que suportam C/C++, Go, Python, REST e mais.
Consumidor — é uma entidade que requer dados do broker. Similar ao caso do produtor, além do consumidor Java incorporado, existem outros consumidores de código aberto a desenvolvedores interessados em APIs que não estejam em Java.
O Kafka armazena dados em tópicos, os quais são enviados pelos produtores a tópicos Kafka específicos, e os consumidores também os leem. Cada tópico tem uma partição ou mais. As informações enviadas a um tópico são armazenadas ao final, em apenas uma dessas partições. Cada uma delas é hospedada por um broker e não pode se expandir por meio de brokers múltiplos.
Existem algumas razões da contínua popularidade e adoção do Kafka no mercado
Escalabilidade: dois importantes recursos do Kafka contribuem para sua escalabilidade. Um cluster Kafka pode se expandir ou encolher (os brokers podem ser adicionados ou removidos) enquanto opera, sem perigo de quedas. Ao mesmo tempo, um tópico Kafka pode ser expandido com o intuito de conter mais partições. Devido ao fato de que a partição não pode se expandir através de brokers múltiplos, sua capacidade está restrita ao espaço de disco do broker. Ser capaz de aumentar o número de partições e de brokers significa que não há limite na quantidade de informação que um tópico sozinho pode armazenar.
Tolerância a falhas e confiabilidade: o Kafka foi projetado de maneira que uma falha com um broker seja detectável por outros em um cluster. Uma vez que cada tópico pode ser replicado em múltiplos brokers, o cluster pode se recuperar de tais falhas e continuar a operar sem nenhuma interrupção de serviço.
Desempenho: os brokers conseguem armazenar e recuperar informações de forma eficiente em uma velocidade super-rápida.
A Figura 1 mostra 1 cluster Kafka que contém 4 brokers e armazena 3 tópicos (t1, t2 e t3). O t1 apresenta apenas 1 partição e é replicado 3 vezes, enquanto o t2 e o t3 têm 2 partições (cada) e são replicados 2 vezes. Fica claro pela imagem que esse cluster consegue sobreviver a uma falha simples do broker sem perder nenhum dado. Ele pode sobreviver a uma falha dupla de broker se os brokers 1 e 4 ou 3 e 4 forem os pares que falharem. Qualquer outro par que falhe fará com que alguns dados sejam perdidos.
Figura 1. Um cluster Kafka simples
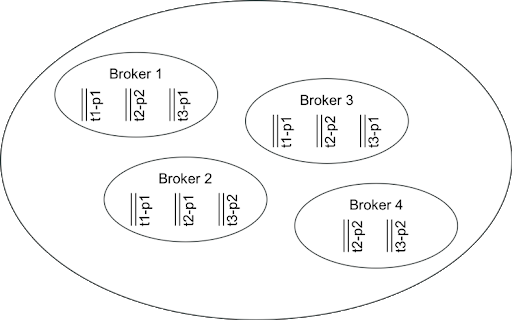 (Fonte: IBM Developer)
(Fonte: IBM Developer)
Uma variedade de configurações de produtores e consumidores pode trabalhar com esse cluster. Por exemplo:
o cliente 1 pode produzir para o tópico 1 (atuando como produtor);
o cliente 2 pode produzir para o tópico 2 (atuando como produtor);
o cliente 3 pode ler dos tópicos 1 e 2 com a finalidade de criar para o tópico 3 (atuando tanto como consumidor como produtor);
O cliente 4 pode ler do tópico 3.
Em certos casos, pode-se ter um fluxo de dados contínuo e em tempo real para alguns desses tópicos. Por exemplo, o tópico 1 contém leituras de temperatura de vários sensores em uma fábrica, enquanto o tópico 2 tem informações detalhadas sobre esses sensores.
Então, o cliente 3 da configuração acima receberia de forma contínua as leituras de temperatura, cruzando os dados com as especificações mais recentes dos sensores, detectando anomalias e reportando-as no tópico 3. Nesse cenário, o cliente 3 é uma aplicação de fluxo simples que lê informações de um ou mais tópicos Kafka, faz um pouco de processamento e cria saídas para outros tópicos Kafka — tudo isso em tempo real.
A análise das informações em tempo real vinda de dispositivos IoT ou ações de usuários em um site são alguns exemplos do que os fluxos Kafka dão conta facilmente. Outros usos estão listados na documentação de fluxos Kafka referenciada no final deste artigo.
Por causa das funcionalidades descritas acima, o Kafka é uma escolha popular para transmitir dados e processos de ELT. Na verdade, o API de fluxos é parte integrante do Kafka e facilita o desenvolvimento de aplicações de fluxo que processam dados em curso. É justo dizer que o Kafka surgiu como uma plataforma de processamento de mensagens em lotes e agora se tornou a plataforma de processamento de fluxos preferida das pessoas. O Kafka Streams pode ainda ser aumentado com outro projeto de código aberto, chamado de KSQL, que simplificou significativamente o desenvolvimento de aplicações Kafka Streams usando declarações do tipo SQL.
O Kafka e o Kafka Streams têm muito mais a oferecer do que foi descrito neste curto artigo. Os materiais referenciados abaixo os descrevem com mais detalhes e fornecem exemplos de códigos. Eles são altamente recomendados a qualquer pessoa que queira ter mais conhecimento de seus interiores e saber a maneira de usá-los na prática.
...
Quer ler mais conteúdo especializado de programação? Conheça a IBM Blue Profile e tenha acesso a matérias exclusivas, novas jornadas de conhecimento e testes personalizados. Confira agora mesmo, consiga as badges e dê um upgrade na sua carreira!
Categorias



















